Longest Common Sequence: Dynamic Problem
Reference: Back to Back SWE - Longest Common Sequence: Dynamic Problem
Longest Common Subsequence
Subsequence: Contiguous할 필요 없다.
예를들어,
let s1 = 'ABCDGH';
let s2 = 'AEDFHR';
이면, A와 D, 그리고 H가 공통되기 때문에 가장 긴 common sequence는 3이다.
Breaking down the problem
s1 - aab
s2 - azb
lcs("aab", "azb")로 정의를 해보자.
- 마지막 글자를 본다. 여기서는 둘 다 모두 “b”기 때문에, 아래와 같이 sub problem이 된다.
1 + lcs("aa", "az")
- 똑같이 마지막 글자를 본다. 여기서는 두 글자가 같지 않기 때문에, 두 글자 중 하나를 지웠을 때 더 큰 max에 해당하는 값을 사용하도록 하자.
1 + max(lcs("a", "az"), lcs("aa", "a"))
여기서 우리가 찾고자 하는 것은, 글자별로 문장을 나누며, 가장 큰 common sequence를 찾는다.
- Recursive하게 값을 구하면, sub-problem의 max값은 1이 나오는 것을 알 수 있고, 그러면 정답으로 2가 돌아온다.
- 가장 끝에 있는 글자들이 둘 다 같으면 둘 다 없애면 되고, 서로가 다르면 하나씩 줄인 다음 더 긴 값을 반환하면 된다.
테이블로 긴 문제를 해결하기
s1 = "AGGTAB"
s2 = "GXTXAYB"
이 두 문자열들을 비교해보자.

- 두 개의 문자열을 표로 도식화하였을 때, 위와 같이 표현할 수 있다.
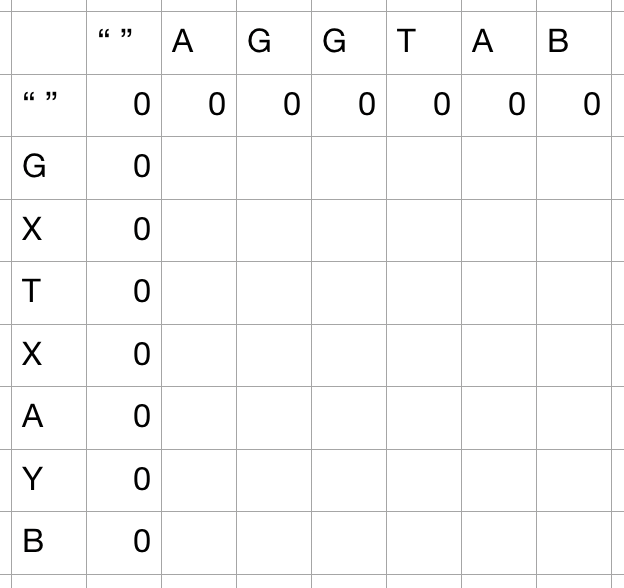
- 우선 가장 기본이 되는 항목들을 채워넣을 수 있다. 보시다시피, 빈 문자열과 다른 문자열의 비교는 무조건 0으로 귀결된다.
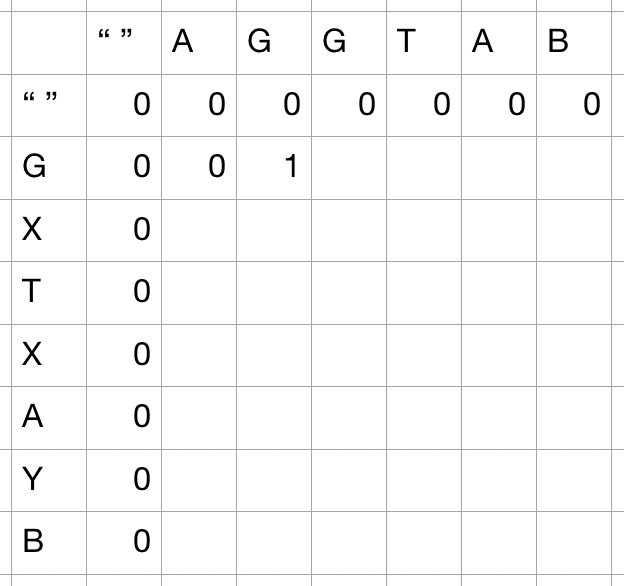
- 첫 번째 숫자는 양쪽이 모두 겹치는 G가 나올 때 기록된다. 이 경우에는, 양쪽 모두 제거가 가능함으로,
1 + lcs("A", "")이 기록된다. 여기서lcs의 결과가 0이므로 1이 기록된다.
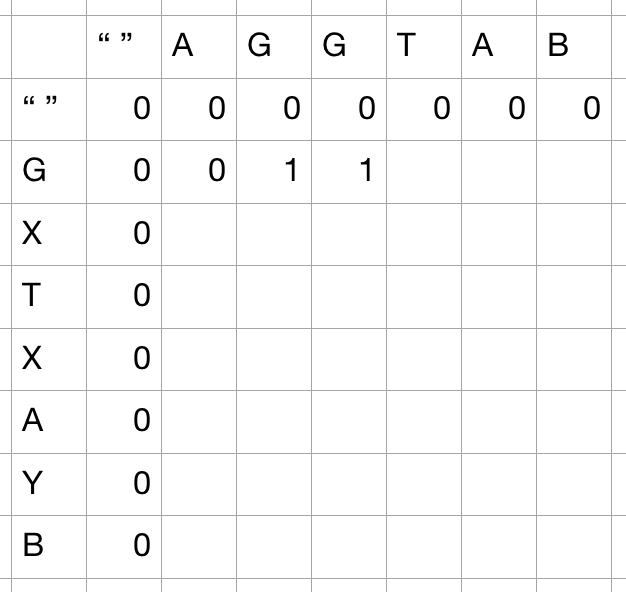
- 두 번째 G가 나왔을 때는 마치 2가 기록될 수 있을 것 같지만, 그렇지 않다. 왜냐면 두 글자가 매칭될 경우 양쪽에서 제거를 하고 나머지를 계산하기 때문이다. 사실상 이 경우에는
1 + lcs("AG", "")가 되며, 이럴 경우 나머지 한쪽에 빈 문자열이기 때문에 따로 숫자가 가산되지 않는다. - 매치가 되지 않는 경우에는 양 쪽에서 한 글자씩 제거한 값 중 max값을 구한다.
max()
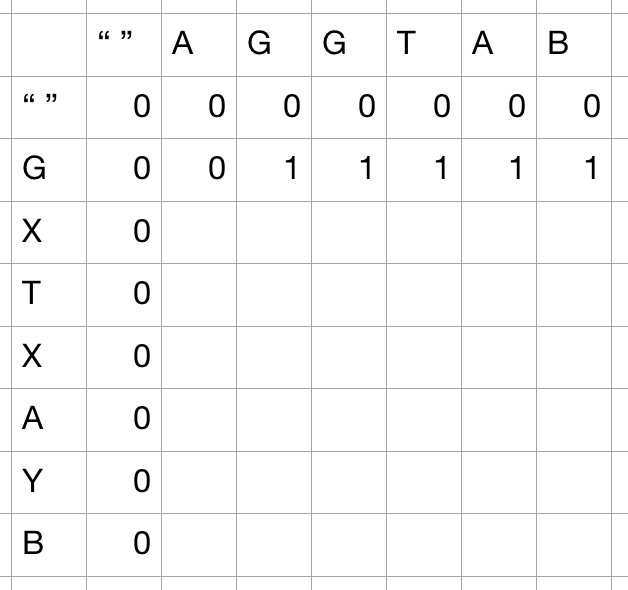
- 이렇게 계산하였을 때, 더 이상의 매치는 발생하지 않았기 때문에 전부 양쪽의 한 글자를 제거한 항목들 중 max값을 반환한다.
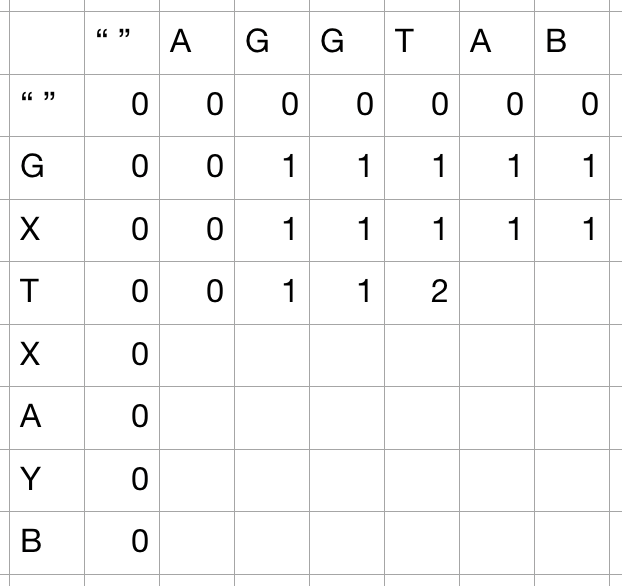
- 두 번째 매치는 양쪽에 T가 등장하였을 때 기록되는데, 이 경우, 양변에서 T를 제거하였을 때 기록된 비교 값을 더해주면 된다.
1 + lcs("AGG", "GX")를 기록하면 되는데, 이 경우 해당 결과값이 1이기 때문에 2로 늘어난다.
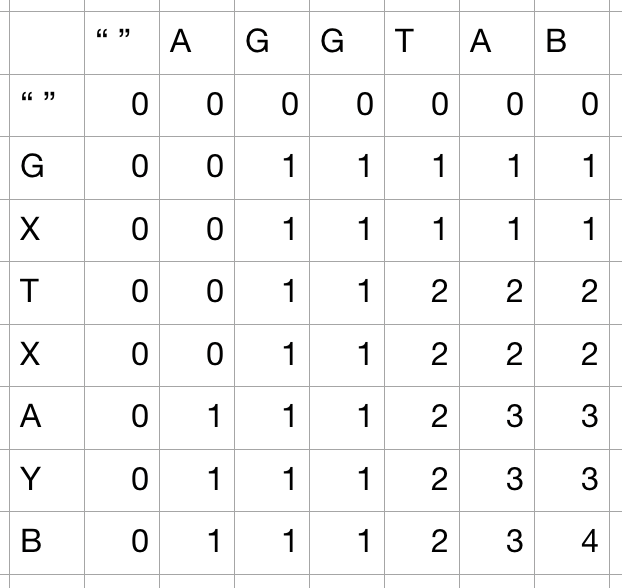
- 마지막 과정까지 반복을 하면 끝까지 숫자를 구할 수 있으며, 가장 최종까지 도착하였을 때 마지막 값은 longest common subsequence가 된다고 할 수 있다.
표가 갖는 의의
표를 통한 도식화는 DP에서 문제 풀이의 이해도를 높이는데 큰 도움을 줄 수 있다. 무엇보다 어떤 순간에 / 어떤 기준을 가지고 / 얼마만큼을 계산할 것인가에 대하여 구체적인 계산을 이끌어낼 수 있기 때문이다.
앞으로 기초적인 DP문제들은 전부 이런식으로 풀어보도록 하자.